Answering Multiple-Choice Questions from Gaokao English Exam
Introduction
For those of us learning English as a second language, English exams, especially those fill-in-the-blank multiple-choice questions can be a challenge.

After contesting English exams and competitions multiple times myself, it’s time for me to retire and coach my own models to do multiple-choice questions answering.

The field of Question Answering has been a well-studied and well-developed area, with great progress over the past few years.
So other than having the model write my homework, what use does multiple-choice question answering have?
To be able to comprehend the question and select the best answer, both in terms of grammar and reasoning, would mean a step forward for artificial intelligence(AI). Furthermore, a good question-answering model could easily be used for more downstream tasks, like generating questions and answer.
In this post, I will walk you through my process of data processing, fine-tuning a GPT2 model, and applying both the GPT2 model and the FitBert model(https://github.com/Qordobacode/fitbert) to answer Chinese Gaokao-level English multiple-choice questions.
Data
Two dataset were used in this project, the first one is Gaokao questions and answers that I scraped from Gaokao Net(http://www.gaokao.com/e/20110512/4dcbca16a78cf.shtml) and Baidu Wenku(https://wenku.baidu.com/view/f550beff32d4b14e852458fb770bf78a64293a54.html); the second one is the RACE dataset developed by Guokun Lai et al. (https://www.cs.cmu.edu/~glai1/data/race/), which contains reading comprehension texts from middle school and highschool English examinations in China.

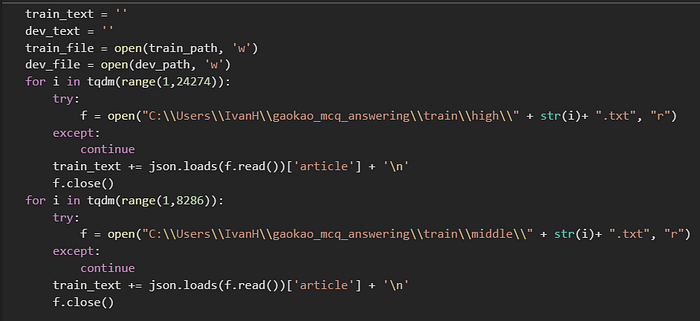
I copy-pasted data from Gaokao net into docx file, and the questions from Baidu Wenku are also available in docx file. Then it’s time to extract questions, options and answers using regular expressions.


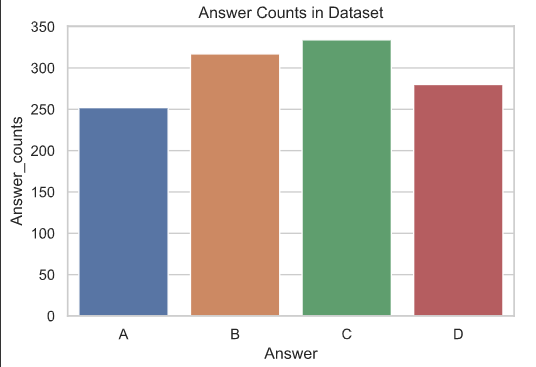
We can see in data analysis that multiple-choice questions have relatively short texts, and almost equally distributed

The RACE dataset came in json format, I used “article” part for raw texts to fine-tune my GPT2 model with.
Methods
We mainly applied two models to do multiple-choice question answering. The fine-tuned GPT2 model and the FitBert Model.
To fine-tune the GPT2 model, we load the RACE dataset into an off-the-shelf GPT2 model from Huggingface and begin training.
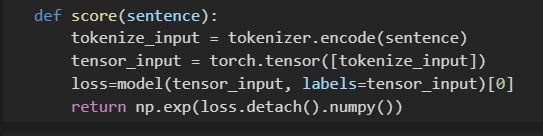
GPT2 models are usually used for text generation. To make it answer questions, we first fill the options into the question blanks, which gives us 4 sentences. We then feed the 4 sentences into our fine-tuned GPT2 model and have it calculate the perplexity. Perplexity is a measure of how “surprised” the model is to see the next word. It should follow that an incorrect answer would be more “surprising” to the GPT2 model, and have a larger perplexity. The model would output the option with the lowest perplexity as its answer.
The idea of using GPT2 models is a viable one. But a flaw inherent in the GPT2 model is that it is a causal language model, and cannot make use of context after the blanks. This is why we added a masked model like the FitBert model, which masks the blanks, and makes use of both contexts before and after the blanks to rank options.

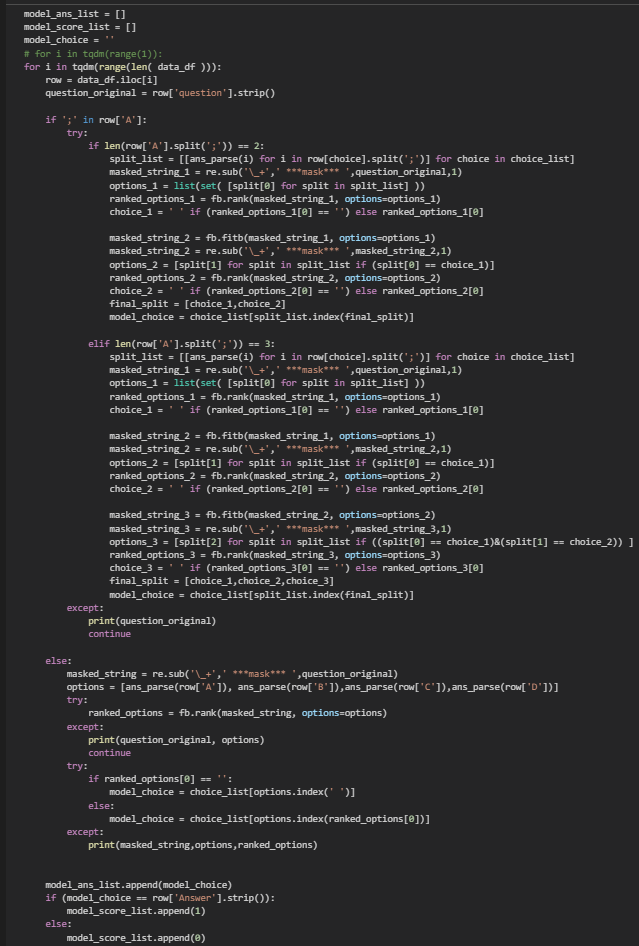
With the models ready, now comes the time to evaluate. The question instances are fed to the two models one at a time, with each model answer, we compare it with the correct answer and record 1 if correct. When the model finishes answering, we sum up the score and calculate the accuracy by:
(Number of correct answers/ Number of questions) * 100%

Results and Discussions
The models’ accuracy is benchmarked against a random guess baseline, which has 25% accuracy. Here we show that the fine-tuned GPT2 model achieved 68.3% accuracy,higher than the untuned GPT2 model, which has 66.9% accuracy. The FitBert model achieved an accuracy of 73.5%.
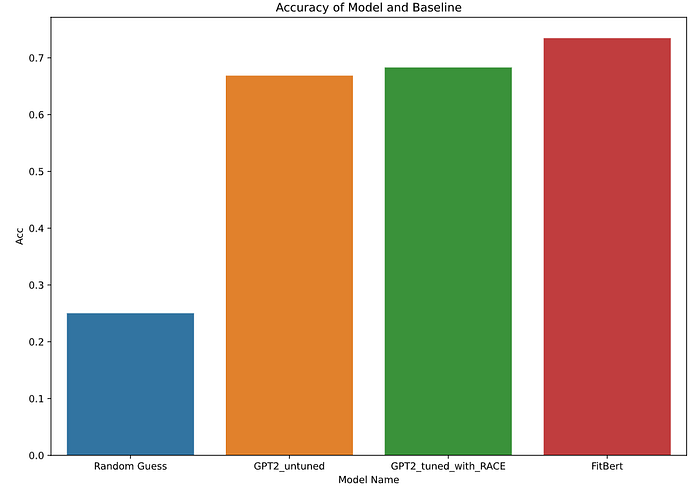
We can see that while the model performance are not on par with a well-trained student, which can achieve 90% to 100% accuracy, they still delivered. Especially, the fine-tuned model outperforming the un-tuned version means that our fine-tuned model is capable of grasping some grammar and logic patterns within Gaokao contexts. The FitBert outperforming the GPT2 models means that the context after the blanks are significant and cannot be ignored.
What’s Next?
Compared with a well-trained student, the GPT2 models are limited to contexts before the blank, which means that they receive less information than a student when doing the questions. The FitBert model, while it could take contexts both before and after the blanks into account, it is limited by the order in which it has to predict. If there are three blanks to fill in, a student could decide on the second blank first, eliminate some options, and then decide on the rest. The FitBert model can only do the predictions in one linear order. Finally, there is domain knowledge.
A well-trained student sees enough questions that they can capture patterns and traps inside the questions. They know when the question text is loring them to pick a seemingly right but incorrect answer, while my models could fall in the traps.
Therefore, if future work were to be done in answering these Gaokao English Exam questions, I would recommending using masked models and try to rank the order of determining the answer as well. More question patterns should also be used to train the model to avoid common traps in questions.
